Wer viele URLs per Skript einholt, kann mit parallel abgefeuerten Requests Zeit sparen. Eine Horde wohlerzogener Prozesskinder hilft, diese Aufgabe elegant abzuwickeln.
Neulich nervte mich ein Monitorskript, das den Status von 26 Servern per Web-Request abfragt: Es dauerte einfach ewig, bis das Endergebnis vorlag. Auch bei schneller Netzwerkverbindung kann ein HTTP-Request eine gute Sekunde dauern und bei 26 sind das ... You do the math! wie der Amerikaner sagt. Muss der Prozessor auf externe Ereignisse wie das Eintreffen von Daten einer lahmen Webseite warten, lässt sich der Vorgang beschleunigen, in dem man möglichst viele dieser langwierigen Prozesse parallel startet.
So stellte ich vor zweieinhalb Jahren in [2] einmal das Modul
LWP::Parallel::UserAgent von Marc Langheinrich vor, das
quasi-parallele Requests abfeuert. Leider unterstützt es
keine https-URLs (SSL-Protokoll) und wegen der
verwegenen Implementierung ist da in naher Zukunft auch keine
Änderung in Sicht.
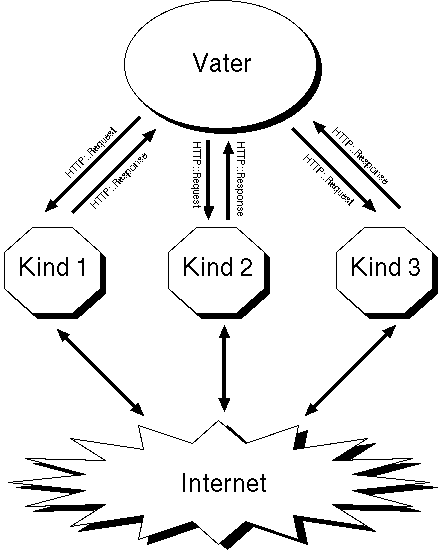
Beim Lesen des Artikels in [3], in dem Meister Schwartz gekonnt mit Pipelines herumjongliert, kam mir folgende Idee: Wie wäre es, wenn ein Vaterprozess ein Dutzend Kinder erzeugte und, wie ein Apache-Server, seinen Sprösslingen regelmässig Web-Aufträge erteilte? Unix-Pipes zu und von den Kindern stellen sicher, dass Aufträge hinunter und Antworten herauf purzeln. Der Vaterprozess ist so immer darüber informiert, welche Kinder gerade arbeitslos herumlungern und kann zügig Aufträge nachschieben, bis alle erledigt sind. Abbildung 1 zeigt die Architekur.
| |
| Abbildung 1: Der Vaterprozess lässt eine Reihe Kinder für sich arbeiten |
pipeKoppelt sich jedoch ein Prozesskind einmal vom Vater ab, leben beide in getrennten Speicherwelten und können sich nicht mehr mal schnell über Variablen verständigen. Aber eine Pipe bietet sich an: Dieses Unix-typische Konstrukt hat wie ein Rohr in der realen Welt zwei Enden. Auf der einen Seite schiebt wer Daten hinein, damit sie auf der anderen Seite jemand abholt:
# Pipeline öffnen
pipe OUT, IN or die "Fehler ($!)";
# Hineinschreiben
syswrite IN, "Hallo!";
# Am anderen Ende auslesen
sysread OUT, my ($data), 6;
print "$data\n";
# => "Hallo!"
Statt print zum Schreiben und dem Diamond-Operator <>
zum Lesen, wie sonst in Perl üblich, verwenden wir
syswrite und sysread, die keine interne
Pufferung betreiben. Sonst kann es nämlich sein, dass der Empfänger auf
etwas wartet, das der Sender längst abgeschickt hat, aber noch
im Ausgabepuffer des Senders herumlungert. syswrite und sysread
hingegen sind die Perl-Äquivalente von write und read in C
und schreiben und lesen einfach drauflos.
Eine Pipeline zwischen Vater und Sohn geht ein bisserl komplizierter:
Der Vater legt sie mit pipe an
und erzeugt mit fork einen neuen Kindprozess.
Dieser erbt alles vom Vater, einschließlich der beiden Handles der
Pipe. Soll nun die Pipe vom Vater zum Sohn zeigen, muss der Vater
von seinen beiden Handles das lesende schließen und der Sohn,
der ja auch beide Handles hat, das schreibende.
Soll sowohl der Vater den Sohn ansprechen, als auch der Sohn den Vater, geht das mit zwei Pipes, die der Vater erzeugt. Anschließend schließt der Vater das lesende Handle der ersten Pipe und das schreibende Handle der zweiten. Der Sohn hingegen schließt das schreibende Handle der ersten Pipe und das lesende Handle der zweiten. So zeigt die erste Pipe vom Vater zum Sohn und die zweite vom Sohn zum Vater. Uff.
selectHat der Vater zehn Kinder, verfügt er über 10 Rückkanäle, auf
denen jeweils Nachrichten von einem der Kinder ankommen können. Bloß
woher weiss er, welches Kind gerade etwas mitteilen will? Ständig durch alle
Kanäle zu rotieren wäre extrem ineffizient. Unter Unix gibt es deshalb
die Funktion select, der man sagen kann: ``Hey, ich habe da zehn
Handles ... sach Bescheid, wenn auf irgendeinem von ihnen eine
Nachricht vorliegt.'' Normalerweise blockt dann das Betriebssystem
den laufenden Prozess solange, bis eines der Handles Daten zum Lesen hat --
und zwar ohne den Prozessor zu belasten. Nun gibt's zwar select auch in
Perl, jedoch steht mit IO::Select ein schöner objektorientierter
Wrapper zur Verfügung. Dieses Modul liegt den heutigen
Perl-Distributionen bereits bei und wir bedienen uns folgender
Methoden:
# Konstruktor
my $watch = IO::Select->new();
# Handle anmelden
$watch->add($handle);
# Blocken und lesebereite
# Handles zurückgeben
my @ready = $watch->can_read();
Der Konstruktor erzeugt ein Überwacher-Objekt $watch,
das über die add-Methode
zu überwachende Handles entgegennimmt.
Als $handle nehmen wir IO::Handle-Objekte, moderne File-Handles, die
die pipe-Funktion erzeugt, falls sie mit Skalaren statt traditionellen
File-Handles aufgerufen wird:
pipe my $in, my $out or
die "pipe failed ($!)";
Wie stellen wir sicher, dass der Empfänger am anderen Ende der
Pipeline auch weiss, wo die gesendete Nachricht aufhört? Es kann
nämlich durchaus passieren, dass der Sender 5000 Bytes abschickt, aber für
den Empfänger kurzfristig nur 4096 Bytes zur Verfügung stehen.
Weiss der Empfänger im Voraus, wie lang die Nachricht ist, kann
er die ausstehenden Bytes nachfordern. Deswegen implementieren wir
ein einfaches Leitungsprotokoll: Als erstes kommt immer eine 8-stellige
Hex-Zahl im Format 0xXXXXXXXX an, die die Länge der nachfolgenden
Nachricht angibt. Heisst die Nachricht "abc", kommt folgendes auf
der Leitung an:
0x00000003abc
Eine achtstellige Hex-Zahl kann bis zu vier Giga-Byte darstellen -- mehr als genug für unsere Zwecke.
StorableDie Kinder nehmen Aufträge als HTTP::Request-Objekte aus
der libwww-Bibliothek von Gisle Aas entgegen, die
der Vater vorher erzeugt hat. Nun kann man nicht einfach Objekte
eines Prozessraums mittels einer Pipe in einen anderen pumpen und
dort verwenden -- schließlich sind wir nicht .NET oder was! Allerdings
bietet das Storable-Modul die Möglichkeit, Objekte beliebiger
Verschachtelungstiefe mit freeze (einfrieren) zu einem String
zu serialisieren und mit thaw (auftauen) wieder zurück
in ein Objekt zu verwandeln.
Genau so funktioniert der heute vorgestellte parallele Greifer: Der Vater
erzeugt HTTP::Request-Objekte, friert sie ein, sendet sie über die
Leitung an ein Kind, welches das Objekt auftaut und den HTTP-Request
durchführt. Das so entstehende HTTP::Response-Objekt wiederum
friert es ein, pumpt es über die Sohn-Vater-Pipeline hoch zum Vater,
der es wiederum auftaut und das Ergebnisobjekt abspeichert.
ForkedUADas heute vorgestellte Modul ForkedUA.pm
(für den mit fork abgespaltenen UserAgent) bietet nach außen folgende
Methoden an:
use ForkedUA;
my $f = ForkedUA->new(
processes => 5,
debug => 1);
$f->register($request);
my @responses = $f->process();
Der Konstruktor new() erzeugt ein neues ForkedUA-Objekt, das
die ganze Komplexität nach außen abschirmt. Es nimmt als optionale
Parameter processes und debug entgegen. processes ist
die Anzahl der verwendeten parallelen Prozesse, 10 ist der Defaultwert.
Und falls debug auf einem wahren Wert steht (default ist falsch),
gibt das Modul einige interessante Meldungen aus, während es geschäftig
URLs vom Netz holt.
Die Methode register nimmt eine oder mehrere Referenzen auf
HTTP::Request-Objekte entgegen, die spezifizieren, welche URLs mit
welchen Parametern ForkedUA holen soll. register kann beliebig
oft hintereinander aufgerufen werden, um weitere Aufträge an den
Webschnapper zu erteilen.
Dann öffnet die process-Methode Schleusen, um die bis dato
eingegangen Aufträge an die Kinder weiterzuleiten und nicht zu rasten
und nicht zu ruhen bis auch der allerletzte Bytezipfel eingetroffen ist.
process gibt einen Array zurück, der als Elemente
HTTP::Response-Objekte enthält -- in der gleichen Reihenfolge, in
der die Aufträge vorher eingingen. Da HTTP::Response-Objekte auch
Referenzen auf die zugehörigen HTTP::Request-Objekte enthalten,
kann man auch so den URL des ursprünglichen Auftrags ermitteln:
$resp->request->uri->as_string.
Listing schnapper.pl zeigt eine Beispielanwendung: Es registriert
in einer for-Schleife
insgesamt neun URLs auf drei verschiedenen Webseiten, lässt
sie von ForkedUA holen und gibt bei Fehlern den Fehlercode und
im Erfolgsfall die Anzahl der eingegangenen Bytes aus:
$ schnapper.pl
24713 Bytes von https://www.verisign.com/ geholt.
17241 Bytes von http://www.yahoo.com/ geholt.
http://yahoo.com/hobined: Fehler 404 (Not Found)
24713 Bytes von https://www.verisign.com/ geholt.
17241 Bytes von http://www.yahoo.com/ geholt.
http://yahoo.com/hobined: Fehler 404 (Not Found)
24713 Bytes von https://www.verisign.com/ geholt.
17241 Bytes von http://www.yahoo.com/ geholt.
http://yahoo.com/hobined: Fehler 404 (Not Found)
Dabei nutzt schnapper.pl das Modul HTTP::Request::Common,
um die HTTP::Request-Objekte einfach durch die mit ihm verfügbare
Funktion GET zu erzeugen.
Wie man sieht, funktioniert ForkedUA nicht nur für ordinäre
http-URLs, sondern auch für SSL (https) und sogar ftp --
weil es einfach die bereits vorhandene Funktionalität des
Standardmoduls LWP::UserAgent nutzt: Kein Haareraufen dank
schlauer Modultechnik vom CPAN! Und der Original-LWP::UserAgent
ist unter der Haube von ForkedUA immer noch erhältlich:
Wie Zeile 17 in schnapper.pl zeigt, bringt ihn die ua-Methode
hervor und man kann an ihm wie gewohnt Proxy- und Timeout-Einstellungen
vornehmen.
01 #!/usr/bin/perl
02
03 use warnings;
04 use strict;
05
06 use ForkedUA;
07 use HTTP::Request::Common;
08
09 my $f = ForkedUA->new(processes => 5);
10
11 foreach my $i (1..3) {
12 $f->register(GET "https://www.verisign.com");
13 $f->register(GET "http://yahoo.com");
14 $f->register(GET "http://yahoo.com/hobined");
15 }
16 # 20 Sekunden Timeout setzen
17 $f->ua->timeout(20);
18
19 # Alle Seiten parallel einholen
20 my @responses = $f->process();
21
22 for my $resp (@responses) {
23 if($resp->is_success) {
24 my $len = length($resp->content());
25 print length($resp->content()),
26 " Bytes von ",
27 $resp->request->uri->as_string(),
28 " geholt.\n";
29 } else {
30 print $resp->request->uri->as_string(),
31 ": Fehler ", $resp->code, " (",
32 $resp->message, ")\n";
33 }
34 }
Nun zur Implementierung von ForkedUA.pm: Zeile 3 deklariert
das Package ForkedUA. Die Zeilen 8 und 9
stellen Warnungen (vor Perl 5.6 war das der -w-Schalter)
und strenge Regeln an. Die nachfolgend hinzugezogenen Module
IO::Select, Tie::RefHash und Storable liegen allesamt
der Perl-Distribution bei, nur LWP::UserAgent und das
vorher in schnapper.pl verwendete HTTP::Request::Common muss
man unter Umständen im libwww-Paket vom CPAN holen.
Die Klassenvariable $DEBUG steuert, ob die in Zeile 37 definierte
Funktion debug tatsächlich die ihr übergebene Meldung
ausgibt oder still schweigt.
Der Konstruktor new ab Zeile 19 legt den Instanzhash an. In ihm
sind ein UserAgent-Objekt und wichtige Zustandsvariablen des
ForkedUA-Objekts, die man durch new übergebene Parameter
überschreiben kann. So ist processes mit 10 vorbesetzt, doch
das unscheinbare @_ am Ende des Instanzhashes hängt ein
eventuell bereitgestelltes processes => 10 hintan und
überschreibt somit die Instanzvariable. Gleiches gilt für debug,
welches später $DEBUG beinflusst.
001 #!/usr/bin/perl
002 ##################################################
003 package ForkedUA;
004
005 # Mike Schilli <m@perlmeister.com>, 2001
006 ##################################################
007
008 use warnings;
009 use strict;
010
011 use IO::Select;
012 use Tie::RefHash;
013 use Storable qw(freeze thaw);
014 use LWP::UserAgent;
015
016 my $DEBUG = 0;
017
018 ##################################################
019 sub new {
020 ##################################################
021 my ($class) = shift;
022
023 my $self = {
024 ua => LWP::UserAgent->new(),
025 reqs => [],
026 status => [],
027 debug => 0,
028 responses => [],
029 processes => 10,
030 @_ };
031
032 $DEBUG = $self->{debug};
033 return bless($self, $class);
034 }
035
036 ##################################################
037 sub debug { print(@_, "\n") if $DEBUG; }
038 sub ua { return shift->{ua} }
039 ##################################################
040
041 ##################################################
042 sub register {
043 ##################################################
044 my($self, @requests) = @_;
045 push(@{$self->{reqs}}, @requests);
046 }
047
048 ##################################################
049 sub process {
050 ##################################################
051 my $self = shift;
052
053 tie(my %handle_to_index, 'Tie::RefHash');
054
055 my $watcher = IO::Select->new();
056
057 # Alle Kinder hochfahren und Kommuni-
058 # kationskanäle aufbauen
059 foreach my $i (0..$self->{processes}-1) {
060 my($down, $up, $pid) = $self->mk_child();
061
062 # Auf die Überwachungsliste
063 $watcher->add($up);
064
065 # Zuordnung Handle => Kind-Index
066 $handle_to_index{$up} = $i;
067
068 # Status dieses Kindes
069 $self->{status}->[$i] = {
070 down => $down,
071 up => $up,
072 busy => 0,
073 pid => $pid
074 };
075 }
076
077 my $busy = 0;
078 my $reqid = 0;
079
080 while(@{$self->{reqs}} or $busy) {
081 $busy = 0;
082
083 # Wartende Kinder mit Arbeit versorgen
084 for my $i (0..$#{$self->{status}}) {
085 if($self->{status}->[$i]->{busy}) {
086 # Kind arbeitet schon
087 $busy++;
088 } else {
089 next unless @{$self->{reqs}};
090 # Es gibt noch Arbeit
091 my $req = shift @{$self->{reqs}};
092 # Arbeitsauftrag versenden
093 pipe_send(
094 $self->{status}->[$i]->{down},
095 freeze($req));
096
097 $self->{status}->[$i]->{busy} = 1;
098 # Index dieses Requests merken
099 $self->{status}->[$i]->{reqid} =
100 $reqid++;
101 $busy++;
102 }
103 }
104
105 # Kinder-Ergebnisse einsammeln
106 for my $up ($watcher->can_read()) {
107 my $resp = thaw(pipe_recv($up));
108
109 # Antwort => Ergebnisarray
110 my $i = $handle_to_index{$up};
111 my $rid =
112 $self->{status}->[$i]->{reqid};
113 $self->{responses}->[$rid] = $resp;
114
115 $self->{status}->[$i]->{busy} = 0;
116 $busy--;
117 }
118 }
119
120 # Alle Kinder runterfahren
121 foreach my $i (0..$self->{processes}-1) {
122 pipe_send($self->{status}->[$i]->{down},
123 "");
124 # Auf Kind warten
125 waitpid($self->{status}->[$i]->{pid}, 0);
126 }
127
128 return (@{$self->{responses}});
129 }
130
131 ##################################################
132 sub pipe_send {
133 ##################################################
134 my($fh, $message) = @_;
135
136 my $bytes = sprintf "0x%08x", length($message);
137 syswrite($fh, $bytes . $message);
138 }
139
140 ##################################################
141 sub pipe_recv {
142 ##################################################
143 my($fh) = @_;
144
145 die "Protocol corrupted" if
146 sysread($fh, my $bytes, 10) != 10;
147 $bytes = hex($bytes);
148
149 my $data = "";
150 while($bytes != 0) {
151 my $read = sysread($fh, my $chunk, $bytes);
152 last unless defined $read;
153 $bytes -= $read; $data .= $chunk;
154 }
155 return $data;
156 }
157
158 ##################################################
159 sub mk_child {
160 ##################################################
161 my $self = shift;
162
163 pipe my $down_read, my $down_write or
164 die "Cannot open Child-Parent pipe: $!";
165 pipe my $up_read, my $up_write or
166 die "Cannot open Parent-Child pipe: $!";
167
168 defined(my $pid = fork) or die "Can't fork\n";
169
170 if($pid) { # Vater => Kindseitige Kanäle
171 # schließen und zurückkehren
172 close($down_read);
173 close($up_write);
174 return($down_write, $up_read, $pid);
175 }
176
177 # Hierher kommt nur das Kind
178 close($down_write);
179 close($up_read);
180
181 # Endlose Arbeitsschleife für das Kind
182 { my $data = pipe_recv($down_read);
183
184 # Kommando zum Beenden erhalten?
185 if($data eq "") {
186 debug "CHILD[$$] shutting down";
187 close($down_read);
188 close($up_write);
189 exit 0;
190 }
191
192 # Auftrag eingegangen
193 my $req = thaw $data;
194 debug "CHILD[$$] received request for ",
195 $req->uri->as_string;
196
197 # Auftrag ausführen
198 my $resp = $self->{ua}->request($req);
199 debug "CHILD[$$] completed request for ",
200 $req->uri->as_string;
201
202 # Response-Objekt zum Vater senden
203 pipe_send($up_write, freeze($resp));
204 # Nächster Request
205 redo;
206 }
207 }
208
209 1;
Die Methode ua in Zeile 38 reicht nur eine Referenz auf das
intern gehaltene LWP::UserAgent-Objekt hoch.
Die register-Methode hängt ihr überreichte HTTP::Request-Objekte
an den unter der Instanzvariablen reqs hängenden Array an.
process schließlich startet zunächst durch wiederholte Aufrufe
der Funktion mk_child sämtliche Kinder. mk_child liefert jedesmal
eine Liste mit
drei Rückgabewerten: Das Sende-Handle für Befehle an das Kind,
das Empfangs-Handle für Nachrichten vom Kind und die Prozess-ID
des Kindes. All dies kommt in ein kind-spezifisches Array, das unter
der Instanzvariablen status hängt. Der Hash %handle_to_index
hilft mit einem kleinen Kniff: Liegt später eine Kindsnachricht vor,
wird die can_read-Methode des IO::Select-Objektes eine Reihe
von Handles zurückliefern -- aber wie wissen wir, zu welchem Kind
in unserem status ein bestimmtes Handle gehört?
Der Hash %handle_to_index ordnet
jedem Handle eine Indexzahl zu, die in status auf den Zustand
des richtigen Kindes zeigt. Nur vertragen Perl-Hashes normalerweise
keine Referenzen als Keys -- diese werden einfach als Strings
interpretiert. Im vorliegenden Fall ging's also sogar, aber
schöner ist's freilich, den Hash mit tie an das
Modul Tie::RefHash zu ketten, wie in der Perl-FAQ beschrieben.
Zeile 84 iteriert über alle Kindprozesse und der Schleifenkörper
prüft, welche von ihnen noch nicht arbeiten. $busy ist dabei
die Anzahl tatsächlich arbeitender
Prozesse. Findet sich ein Arbeitsloser, sendet
pipe_send ihm über das oben besprochene Leitungsprotokoll ein
mit Storable::freeze eingefrorenes HTTP::Request-Objekt zu.
In $rid und dem Hasheintrag reqid unter status
merkt sich ForkedUA die Indexzahl des Requests aus dem ursprünglichen
Request-Array. Schließlich trudeln die Ergebnisse wegen der
Parallelität der Prozesse in zufälliger Reihenfolge ein und für
den Ergebnisarray wollen wir die ursprüngliche Ordnung beibehalten.
Zeile 106 wartet auf Nachrichten von Kindern, die ihren Auftrag
abgewickelt haben. can_read liefert hierzu ein oder mehrere
IO::Handles, welche die pipe_recv-Funktion sofort anzapft und
das daraus hervorsprudelnde HTTP::Response-Objekt mit
Storable::thaw auftaut.
%handle_to_index findet den zum Handle passenden Datensatz
in status, wo das HTTP::Response-Objekt mit demjenigen
Index unter responses eingeordnet wird, unter dem der ursprüngliche
Request in der Auftragskette stand. Das $busy-Flag erhält
den Wert 0 zugewiesen, denn das Kind ist bereit für die nächste
Aufgabe.
Dieser Reigen geht solange weiter, bis es keine Aufträge mehr
gibt und alle Kinder von ihren letzten Missionen zurückgekehrt sind.
Die foreach-Schleife in Zeile 121 klappert dann alle Kinder ab und
sendet ihnen einen leeren String -- worauf diese sich ohne Murren
beenden, wie wir weiter unten sehen werden. Die Funktion
waitpid() sorgt für ein ordnungsgemäßes Begräbnis ohne
dass die Gefahr besteht, dass die Untoten später noch als Zombies
herumgeistern.
Die Funktion mk_child ab Zeile 159 erzeugt zunächst die zwei Pipes
mit insgesamt vier Handles. Aus dem fork-Befehl in Zeile 168
gehen sowohl Vater als auch Sohn hervor, mit dem Unterschied, dass
$pid im Vaterprozess die Prozess-ID des Sohnes enthält, während
$pid im Sohn gleich 0 ist. So lässt die if-Bedingung
in Zeile 170 nur den Vater durch, der unnütze Handles schließt
und sofort zurückkehrt.
Der Sohn hingegen macht bei Zeile 178 weiter, schließt seinerseits nicht gebrauchte Handles und startet die (beinahe) Endlosschleife ab Zeile 182, die auf Aufträge vom Vater wartet, diese bearbeitet, das Ergebnis zurückliefert und wieder auf neue Aufträge wartet. Ist der Auftrag vom Vater ein leerer String, weist Zeile 185 zur letzten Ölung: Nach dem Schließen aller noch offenen Handles beendet sich der Kind-Prozess.
Eintreffende HTTP::Request-Objekte taut Zeile 193 mit Storable::thaw
auf. Der LWP::UserAgent holt die entsprechende Webseite ein und
Zeile 203 pumpt das eingefrorene HTTP::Response-Objekt zum Vater
hoch. Der freut sich, weil schon wieder Auftrag erledigt ist.
Viel Spaß beim Webschnappen mit Überlichtgeschwindigkeit
-- bis zum nächsten Mal!
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |