Im Editor vim (VI IMproved) stecken eine Unzahl von Tricks,
die im Programmieralltag die Tipparbeit reduzieren. Der
heutige Snapshot zeigt eine Auswahl der effektivsten
Sparmaßnahmen für Perl-Hacker.
Keine Wahl, die ein Programmierer im Leben trifft, ist so entscheidend und so unwiderrufbar wie die Wahl eines Editors. Wer sich einmal für vi oder Emacs entschieden hat, bleibt üblicherweise dabei und setzt alles daran, auch noch den letzten Trick aus dem permanent genutzten Werkzeug herauszufieseln. Wer effektiver mit dem Editor arbeitet, reduziert nicht nur die Gefahr, am Carpal-Tunnel-Syndrom zu erkranken, sondern programmiert erheblich schneller und mit weniger Tippfehlern.
Der Editor vim ist seinem altersschwachen Kollegen vi um
einiges voraus. vim wurde über die Jahre für Vieltipper
hochgezüchtet, lässt sich bis ins Detail konfigurieren, mit
Plugins erweitern und so ganz nach Geschmack an den
persönlichen Arbeitsstil anpassen. In der Konfigurationsdatei
.vimrc im Home-Verzeichnis lassen sich alle heute vorgestellten
Tricks dann permanent abgelegen.
Da Linux-Distributionen nicht immer der neueste vim beiliegt,
prüft man am Besten mit
vim --version
nach, welche Version vorliegt. Bei weniger als 6.1 empfiehlt sich ein Upgrade.
Farblich unterlegte Schlüsselworte erleichtern das Verstehen von
komplexeren Code-Gebilden erheblich. vim beherrscht das
Syntax-Highlighting von allerlei Programmiersprachen ganz
hervorragend und produziert selbst für das schwer zu parsende Perl
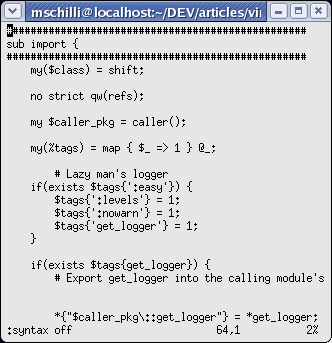
erstaunlich präzise Ergebnisse. Abbildung 1 und 2 zeigen, wie viel
einfacher farblich herausgestellte Code-Konstrukte erkennbar sind.
Vorraussetzung ist lediglich, dass das benutzte xterm Farben
unterstützt. Falls nicht schon von Anfang an eingestellt, stellt das Kommando
:syntax on das Syntax-Highlighting an. Falls vim an der
Datei-Endung (.pl oder .pm) oder auch am Inhalt (Shebang-Zeile
enthält etwas wie #!/usr/bin/perl) erkennt, dass es sich um
Perl-Code handelt, kommen die Konstrukte schön zum Vorschein.
Falls eine neue Datei editiert wird, deren Name keine spezifische
Perl-Endung hat und die zum Zeitpunkt des vim-Aufrufs
noch keine Shebang-Zeile aufwies, lässt sich der Dateityp
nachträglich mit
:set filetype=perl
auf Perl einstellen.
| |
| Abbildung 1: vim ohne ... |
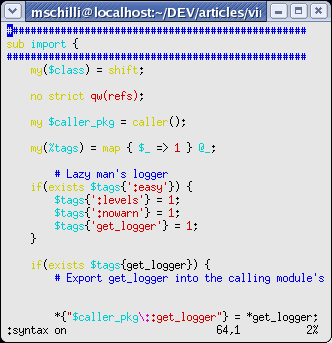 |
| Abbildung 2: ... und mit Syntax-Highlighting. |
Wer ständig in der gleichen Sprache programmiert, wiederholt laufend die gleichen Tippmuster. Als Log::Log4perl-Advokat kann ich zum Beispiel schon nicht mehr zählen, wie oft ich
use Log::Log4perl qw(:easy);
getippt habe. Zum Glück hat das jetzt ein Ende, denn das Kommando
:abbreviate ul4p use Log::Log4perl qw(:easy);<RETURN>
definiert die Abkürzung ul4p. Sobald im Texteingabe-Modus die Zeichenfolge
ul4p getippt und mit einem Wortbegrenzer wie der Leer- oder Enter-Taste
abgeschlossen wird, expandiert vim die Folge automatisch zum vordefinierten
Ausdruck. Ein wörtlich eingetipptes <RETURN> am Ende der Definition
simuliert das Drücken der Enter-Taste.
Wer nach der Expansion nicht im Eingabemodus bleiben, sondern
in den Kommandomodus wechseln möchte, hängt einfach ein
(ebenfalls ausgeschriebenes) <ESC>
hintenan.
Eine weitere Möglichkeit, mit einer Abkürzung ein längeres Textstück
in den Text zu holen, ist, vim eine Datei hereinholen zu lassen:
:abb ul4p <BACKSPACE><ESC>:r ~/.tmpl_l4p<RETURN>
Sobald nun ul4p im Text getippt wird und anschließend ein Wortbegrenzer,
ersetzt vim die Abkürzung nahtlos mit dem Inhalt der angegebenen Datei.
Wiederkehrende Editierschritte, die Modifikationen mehrerer, unzusammenhängender Bereiche erfordern, lassen sich elegant mit Makros duplizieren. Abbildung 3 zeigt drei Funktionsköpfe, die es jeweils in Kommentare einzuranken gilt, wie in Abbildung zwei gezeigt.
Dazu sind
folgende Kommandos nötig: Erst mit /sub nach sub suchen, dann den
Makro-Recorder einschalten, den ersten Funktionskopf einranken,
den Makro-Recorder ausschalten. Dann mit n nach dem nächsten
sub suchen und mit @a wieder das Makro abspielen lassen.
Hier sind die Kommandos zusammengefasst:
# Nach 'sub' suchen
/sub
# Makro-Rekorder
# für Makro a einschalten
qa
# Zeile darüber einfügen,
# zurück in Kommandomodus
O<ESC>
# 20 '#'-Zeichen einfügen
20i#<ESC>
# Zeile kopieren
yy
# Eine Zeile nach unten fahren, kopierte Zeile
# unterhalb einfügen.
jp
# Makro-Rekorder beenden
q
# Nach dem nächsten 'sub' suchen
/sub
# Macro 'a' abspielen
@a
# ... wiederholen.
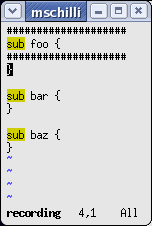 |
| Abbildung 3: Der Macro-Editor während der Aufnahme ... |
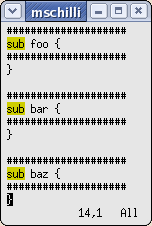 |
| Abbildung 4: ... und der Nutzer spielt das Macro danach einfach zweimal ab. |
Wer gleich von Anfang an neue Funktionen mit Kommentaren einranken möchte, definiert sich ein neues Kommando auf die Taste ``F'':
:map F o<ESC>43i#<ESC>yyosub {<ENTER><ESC>Pk$i
Drückt der Benutzer dann ``F'' im Kommandomodus,
fügt vim den Funktionskopf ein und positioniert
den Cursor gleich im Eingabemodus an die richtige Stelle:
###########################################
sub {
^ (Cursormarkierung)
###########################################
Der Buchstabensalat in der map-Definition besteht auch wieder
aus den vi-typischen
Ein-Tasten-Kommandos im Kommandomodus, die jeder vi-Enthusiast auswendig
kennt. Die Anzahl der Hashmarks ist Geschmackssache, in der Definition oben
wurden 43 gewählt.
Bei sich ständig wiederholenden Sequenzen wie Funktionsköpfen
sparen map-Kommandos enorm Zeit und Nerven. Wer möchte, kann
das Kommando noch an die privaten Bedürfnisse anpassen, oft
genutzte Parameterübergaben der Art
my(...) = @_;
bieten sich an.
Eine weitere, sich häufig wiederholende Aufgabe ist das Sichern eines
gerade bearbeiteten Skripts mit :w und der Aufruf
perl -c skript.pl
um festzustellen, ob sich in das Skript soweit Fehler eingeschlichen haben. Der folgende Befehl legt die Aktionen ``sichern'' und ``perl -c ausführen'' einfach auf die Taste ``X'' (großes X) im Kommandomodus:
:nnoremap X :w<Enter>:!perl -c %<Enter>
Wird statt :map der Befehl :noremap verwendet, wird das ``X''
niemals auf der rechten Seite eines anderen map-Ausdrucks evaluiert.
Und :nnoremap führt die Definition nur im Normal- (also im Kommando-)
Modus durch. Der Platzhalter % wird durch den Namen der aktuell
editierten Datei ersetzt.
Bei längeren Texten wie POD-Dokumentation stellt sich locker fließender Erzählstil erst beim siebten oder achten Umschreiben ein. Wer dabei fleißig einfügt und wieder ausstreicht, erzeugt zerfledderte Absätze, die schwer korrekturzulesen sind. Textverarbeiter wie Word arbeiten ständig im Hintergrund, um die Absätze umzuformatieren, echte Hacker müssen die Ecken selbst ausbügeln.
Mit vim geht das mit nur vier Tastendrücken im Kommandomodus:
{-g-q-}. Zuerst fährt { an den Anfang des gegenwärtigen Absatzes,
das Kommando gq (wohl abgeleitet vom englischsprachigen Magazin GQ)
bricht die Zeilen im Flattersatz um, und das abschließende }
bestimmt die Reichweite des Kommandos: Bis zum Ende des Absatzes.
Noch eleganter geht es mit dem Perl-Modul Text::Autoformat von
Großmeister Damian Conway. Neben Flattersatz kennt es auch noch allerlei
intelligente Umbrüche: So kann es mit Aufzählungen umgehen
(nachfolgende Zeilen eines Aufzählungspunktes
werden entsprechend eingerückt) und auch
mit > oder >> oder mehr Eckchen eingerückte
Email-Zitate behandelt es, wie ein Mensch das tun würde.
Wer sich das Kommando
:map f !Gperl -MText::Autoformat -e'autoformat'<RETURN>
definiert, drückt im Kommandomodus einfach die Taste f, während
der Cursor irgendwo in einem Textabsatz steht, und schon wird
dieser automatisch und sachgemäß formatiert.
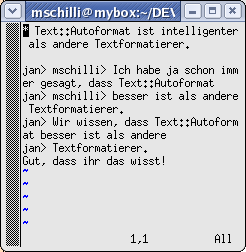 |
| Abbildung 5: Eine Auflistung und ein Abschnitt aus einer Email vor ... |
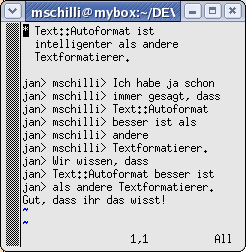 |
| Abbildung 6: ... und nach dem Formatieren mit Text::Autoformat |
Wer die standardmäßig eingestellte Zeilenlänge von 72
Zeichen als zu breit (oder zu schmal) empfindet, kann sie mit
der option right variieren:
:map f !Gperl -MText::Autoformat -e'autoformat {right=>65}'<RETURN>
Erfahrene vim-Nutzer merken natürlich sofort, dass f im Kommandomodus
schon vorbelegt ist: Der Cursor springt bis zum nächsten eingegebenen
Zeichen vor, fe springt so bis zum nächsten e im Text. Wer diese
Funktion tatsächlich nutzt, sollte einen anderen Buchstaben wählen
oder auch gerne eine Zweierkombination
einstellen:
:map !f ...
reagiert im Kommandomodus erst, wenn zuerst ! und dann f
eingegeben wird.
Über die Formatierung von Programmcode ist schon viel gestritten worden.
Wo kommen die geschweiften Klammern hin? Wie tief wird verschachtelter
Code eingerückt? Mit Leerzeichen oder mit Tabs? Da jeder Programmierer
seinen eigenen Geschmack hat, bietet vim genug Optionen.
Beim Einrücken mit Tabs scheiden sich die Geister, viele lehnen sie völlig
ab. Ist die Option
:set expandtab gesetzt, wandelt vim alle Tabs in Leerzeichen um.
Die Anzahl der Leerzeichen pro Tab bestimmt die Option
:set shiftwidth=4
Wer allerdings expandtab blindlings setzt, läuft böse auf, wenn ein
Makefile editiert wird: Dort sind Tabs vor den Kommandos für eine Target
tatsächlich notwendig. Werden sie durch Leerzeichen ersetzt, ist dies
ein Syntaxfehler. Die Lösung ist, vim per autocmd den Dateityp feststellen
zu lassen, und nur bei erkanntem Perl-Programm die Option
expandtab zu setzen:
:filetype on
:autocmd FileType perl :set expandtab
Eine nützliche Option, um sonst unsichtbare Zeichen sichtbar
zu machen, ist :set list. Alle Tabs erscheinen als ^I und
das Zeilenende ist mit einem blauen '$' mariert.
:set nolist schaltet wieder zurück in den Normalmodus.
Die oben vorgestellte Option shiftwidth hat noch eine weitere
Funktion: Zusammen mit der Option cindent lässt sich so
ordentlich Tipparbeit sparen, denn sobald ein Konstrukt wie
if($really) {
_
eingetippt und die Return-Taste gedrückt wird, rückt vim die nächste
Zeile entsprechend shiftwidth und expandtabs bereits ein. Tippt
der Benutzer allerdings } und ein Return, schiebt vim die schließende
Klammer ebenfalls automatisch wieder an den Zeilenanfang zurück.
Da dieses Verhalten ebenfalls nicht für alle Dateiarten geignet ist,
empfiehlt sich gleichermaßen ein Auto-Kommando, das erst den File-Typ prüft,
bevor die Option gesetzt wird:
:autocmd FileType perl :set cindent
Manchmal stellt sich allerdings erst dann heraus, dass ein Code-Stück
in einen Block muss, wenn es schon getippt wurde. Dann setzt man, wie
in Abbildung 7 gezeigt, einfach geschweifte Klammern darum und tippt
im Kommandomodus die Tastenfolge >i{, um den 'inneren' Block eine
shiftwidth-Breite nach rechts einzurücken, wie Abbildung 8 zeigt.
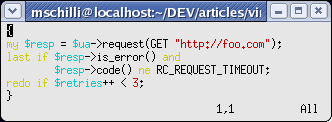 |
| Abbildung 7: Ein Block mit geschweiften Klammern, Cursor auf dem Blockstart ... |
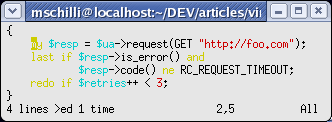 |
| Abbildung 8: und das Kommando >i{ rückt den inneren Block ein. |
Die Option :set smarttab setzt bei gesetzter expandtab-Option noch eins
drauf: Ein Backspace im Eingabemodus auf dem ersten Zeichen
einer eingerückten Zeile rückt die
Zeile wieder aus, und ein Druck auf die Tab-Taste rückt sie wieder ein,
ohne dass richtige ``Tabs'' im Spiel sind.
Noch ein Tipp:
Um von einer geschweiften Klammer zur korrespondierenden zu springen,
genügt es, den Cursor auf eine Klammer zu positionieren, und dann
die Prozenttaste (%) im Kommandomodus zu drücken.
So lässt sich leicht feststellen, wo eine geschweifte Klammer fehlt, wenn
perl einen Syntaxfehler anzeigt.
Wer einmal an einem Computer mit amerikanischer Tastatur sitzt, und
mit vi einen Umlaut wie Ä eintippen möchte, der kann dies mit der Sequenz
Ctrl-K A : im Eingabemodus tun. Das scharfe ß kommt mit
Ctrl-K s s zustande. Die vollständige Tabelle aller so verfügbaren
Umlaute bringt das Kommando :digraphs zum Vorschein.
Ein neues Perl-Skript startet man recht einfach mit dem tmpl-Tool
von [4]: Der Aufruf
$ tmpl -p cooltool
legt eine neue Datei cooltool an. Wie Abbildung 9 zeigt, besteht das
Skript-Skelett aus einigen Kopfzeilen, einigen typischen
Modulen für Skript-Optionen und Manualseitenanzeige. tmpl bezieht
einige konfigurierbare Parameter aus der Datei .tmpl im Home-Verzeichnis
des Benutzers:
# ~/.tmpl
AUTHOR Mike Schilli
YEAR 2005
EMAIL cpan@perlmeister.com
Das Skelett cooltool kann schon zwei Dinge:
$ cooltool -v
zeigt die gegenwärtige Skriptversion an, die in der Variablen
$CVSVERSION liegt und mittels CVS automatisch aufgefrischt wird.
Weiter hilft Pod::Usage, dass die Option -h eine kurze Bedienungsanleitung
ausgibt:
$ cooltool -h
Usage:
cooltool -xyz
Den Rest muss ein zukünftiger Skriptautor dann selbst ausfüllen, aber mit dieser Grundlage ist schon viel erreicht: Ein Grundgerüst, und auch ein Rahmen für Dokumentation, ohne die jedes Skript bekanntermaßen wertlos ist. Pod::Usage sorgt dafür, dass das Skript seine eigene Dokumentation ausgibt, falls etwas schief geht.
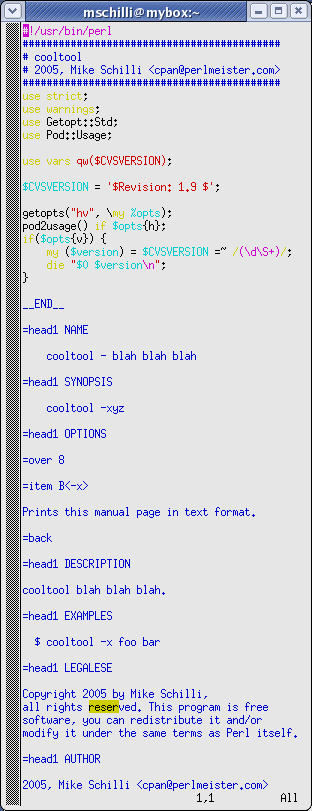 |
| Abbildung 9: Ein Template für eine neues Skript 'cooltool'. |
vim behält geschriebene Wörter automatisch im Kopf und komplettiert
später angefangene Wörter mit der Tastenkombination CTRL-n im Textmodus.
Wer also irgendwo Variablen wie in
our $GLOBAL_SUPER_VARIABLE;
our $GLOBAL_OTHER_VARIABLE;
definiert und sie später wieder verwendet, muss nicht den ellenlangen Namen wieder abtippen, sondern schreibt lediglich die ersten paar Buchstaben und drückt dann CTRL-n:
sub foo {
print $GL CTRL-n
und schon betätigt sich vim als Gedankenleser:
sub foo {
print $GLOBAL_SUPER_VARIABLE
Falls, wie oben, mehrere Möglichkeiten zur Komplettierung führen, kann man mit weiteren CTRL-n vorwärts und mit CTRL-p rückwärts durch die Vorschläge fahren. Ein beinahe triviales Feature, das aber im Lauf der Zeit enorm viel Zeit und Tipparbeit spart.
C-Programmierer kennen das Programm ctags, das eine tags-Datei
für vim erzeugt. Wird diese eingelesen, muss der Entwickler
eines Programmes einfach den Cursor irgendwo auf einen Funktionsaufruf
positionieren, und CTRL-] im Kommandomodus drücken, schon springt
vim zur zugehörigen Funktionsdefinition.
Um vim zu veranlassen, zur Source-Datei von LWP::UserAgent zu springen,
falls der Cursor irgendwo auf LWP::UserAgent in
my $ua = LWP::UserAgent->new();
steht, müssen zwei Dinge erledigt werden: vim muss verstehen, dass
in Perl ein Schlüsselwort auch Doppelpunkte enthalten kann:
:set iskeyword+=:
und die tags-Datei, die alle installierten Packages indiziert hat, muss eingelesen werden:
:set tags=/home/mschilli/.ptags.txt
Dann springt CTRL-] in die Modul-Source, wenn der Cursor auf einem
Modulnamen steht. Alternativ kann man den Modulnamen auch
im Kommando :tag LWP::UserAgent angeben.
Einmal in der Bibliotheksdatei angelangt, genügt ein CTRL-T,
um wieder zurück zum Ausgangspunkt zu navigieren.
Wenn der Cursor auf einem Modulnamen wie LWP::UserAgent
steht, springt CTRL-] zur Zeile package LWP::UserAgent;
in /usr/lib/perl5/site_perl/5.8.5/LWP/UserAgent.pm. Falls
LWP::Debug::trace unter dem Cursor liegt, springt vim
statt dessen die Zeile sub trace { ... in
/usr/lib/perl5/site_perl/5.8.5/LWP.pm an. Die ganze Magie steckt
in der Tags-Datei .ptags.txt, die das weiter
unten vorgestellte Listing ppitags erzeugen wird.
Trotz Window-Manager ist es manchmal sinnvoll, zwei Dateien gleichzeitig
in einem Fenster zu sehen. Welcher vim-User greift schon freiwillig
auf die Maus zurück, wenn die Hände auf der Tastatur bleiben können?
Wer statt CTRL-] die Kombination CTRL-W-] tippt, während
der Cursor auf einem Schlüsselwort steht, dessen Fenster
teilt sich in zwei Hälften: In der unteren bleibt der Code der editierten
Datei sichtbar, in der oberen erscheint der Code des referenzierten
Moduls. Zwischen den Fensterhälften springt man mit CTRL-WW hin
und her. Das Kommando :quit im oberen Fenster schließt letzteres und das
Hauptfenster gehört wieder ganz der ursprünglich editierten Datei.
Alternativ schließt der Befehl :only im unteren Fenster das Obere.
Die vim-Session in Abbildung 10 zeigt unten ein editiertes Testskript, dass das Modul LWP::UserAgent verwendet, und oben die new()-Methode im Sourcecode des Moduls.
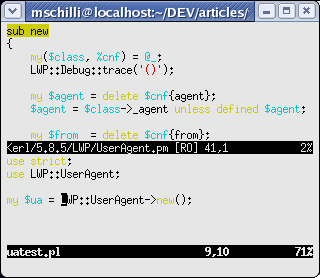 |
| Abbildung 10: vim mit gespaltenem Fenster: Unten ein Testskript, oben der Sourcecode des verwendeten Moduls LWP::UserAgent. |
Weiss man den Namen eines gesuchten Moduls nicht genau, reicht es,
einen regulären Ausdruck anzugeben. Das Kommando tselect sucht
nach allen passenden Tags und bietet eine Liste zur Auswahl an:
:tselect /^LWP
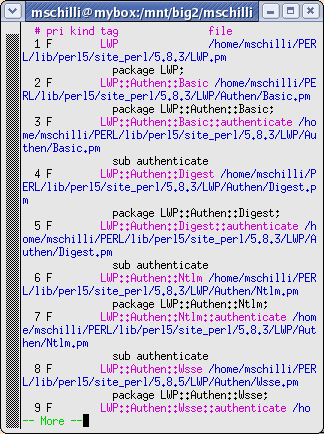 |
| Abbildung 11: Tagsuche per regulärem Ausdruck nach C bringt ein Menü mit numerierten Treffern. |
In Abbildung 11 muss der Benutzer dann nur den passenden Treffer per Nummernmenü auswählen.
Wie kommt ~/.ptags.txt zustande? Hierzu müssen regelmäßig sämtliche
Module der lokalen Perl-Installation durchforstet werden. Das Skript
in Listing ppitags klappert alle @INC-Pfade ab, merkt sich in
@dirs, wo es schon mal war und wird auch bei überlappenden Pfaden
nicht zweimal denselben durchforsten.
Um Perl-Source zu analysieren, braucht man eigentlich perl, denn
Perl ist extrem schwierig zu parsen. Allerdings hat Adam Kennedy vor
kurzem das Unmögliche gewagt und einen ``Good-enough''-Parser für Perl
geschrieben, der wirklich erstaunlich gut ist. Das PPI-Modul vom
CPAN enthält PPI::Document, dessen Methode load() ein Perl-Modul
einliest, in Tokens zerlegt und in einer Baumstruktur ablegt.
ppitags nutzt File::Find, um alle Verzeichnisse in Perls globalem
Array @INC zu durchlaufen. Nur der ebenfalls in @INC
enthaltene Pfad "." wird ausgelassen.
Für jeden gefundenen Eintrag springt
File::Find die Funktion file_wanted an. Falls der gefundene
Eintrag ein Verzeichnis und keine Datei ist, frischt Zeile 28 den
Hash %dirs auf, um festzustellen, ob der Pfad schon durchlaufen wurde.
Falls ja, setzt Zeile 27 die Variable $File::Find::prune auf 1, um
File::Find mitzuteilen, dass es sich den Rest des Verzeichnisses
und alle Unterverzeichnisse
sparen kann. Zeile 31 weist alles außer Perl-Modulen mit der Endung
.pm zurück.
Zeile 33 parst das aktuell gefundene Perl-Modul. Falls irgendwelche Fehler auftreten, fängt Zeile 35 diese ab (PPI ist noch nicht perfekt), spuckt eine Warnung aus und lässt das problemhafte Modul sausen.
Konnte das Modul erfolgreich eingelesen werden, ruft Zeile 41 die
find()-Methode des PPI::Document-Objekts auf, das die
Tokens der Perl-Source durchschreitet und für jeden gefundenen
die ab Zeile 45 definierte Funktion document_wanted aufruft.
Diese prüft, ob es sich beim gefundenen Token um ein
Objekt vom Typ PPI::Statement::Package oder PPI::Statement::Sub
handelt, also eine package oder sub Definition im Perl-Code.
Eine package-Definition besteht aus einer Zeile wie
package LWP::UserAgent;
und das sind in der PPI-Welt vier Tokens: package, Leerzeichen,
der Modulname und der abschließende Strichpunkt. Für die Belange von
ppitags interessiert nur der Modulname, also das dritte Kind
des Knotens, der in $_[1] übergeben wurde. Die Methode child()
mit dem ab 0 gezählten Kinderindex fördert den String "LWP::UserAgent"
zutage: $_[1]->child(2).
Wird eine package-Definition durchlaufen, speichert ppitags dessen
Package-Namen
als aktuelles Package, was zwar durch package-Definitionen in Blocks
leicht ausgehebelt würde, aber das spielt in 99.9% aller Fälle keine
Rolle. ``Good enough'' auch hier.
Zeile 55 stöbert Funktionsdefinitionen der Form sub func { auf
und extrahiert den Funktions- oder Methodennamen,
damit der Tag-Mechanismus Konstrukte wie LWP::Debug::trace
erkennt und später zu der Stelle springt, an dem die Funktion
trace im Modul LWP::Debug definiert ist.
Der push-Befehl in Zeile 64 schiebt einen neuen String ans
Ende des Arrays @found, der aus dem gesuchten Tag (Package-
oder voll qualifizierter Funktionsname), dem absoluten
Source-Dateinamen und einem regulären Ausdruck besteht, der
die package- oder Funktionsdefinition in der Source-Datei
findet. Hierzu bildet die ab Zeile 72 definierte Funktion
regex_from_node einen regulären Ausdruck, der aus
allen Zeichen der Trefferzeile, vom Zeilenanfang bis zum
gesuchten Token, besteht. Bei einer Subroutine liefert
$node->content() sowohl Funktionskopf als auch den Rumpf.
Deswegen schneidet Zeile 78 alle Zeilen außer der ersten ab
und die Zeilen 80/81 gehen solange im Token-Baum zurück, bis der
Zeilenanfang erreicht ist. Nach dem Ende der while-Schleife
steht in $regex der Inhalt der Source-Zeile, vom Zeilenanfang
bis zum Token. Daraus baut Zeile 88 einen regulären Ausdruck
der Form /^.../ mit einem Anker für den Zeilenanfang.
Die Ersetzung eine Zeile vorher stellt sicher, dass enthaltene
Sonderzeichen nicht mit vim-spezifischen Regex-Metazeichen kollidieren,
indem sie sie allesamt mit einem Backslash maskiert.
ppitags erzeugt eine Liste von dreispaltigen
Einträgen in ~/.ptags.txt im Format
Package/Subroutine [tab] Dateiname [tab] Regex
die vim mit :set tags= wie oben beschrieben einliest und
damit elegant von Schlüsselworten zum entsprechenden Sourcecode
springt.
ppitags sollte einmal pro Tag per Cronjob aufgerufen werden, damit
~/.ptags.txt immer auf dem neuesten Stand ist. Wer möchte, kann
das Skript noch dahingehend
erweitern, dass vim voll qualifizierte our-Variablen
(wie zum Beispiel
$Text::Wrap::columns) erkennt und zu deren Definition in der
Modul-Source springt.
01 #!/usr/bin/perl -w
02 use strict;
03
04 use PPI::Document;
05 use File::Find;
06 use Sysadm::Install qw(:all);
07 use Log::Log4perl qw(:easy);
08
09 my $outfile = "$ENV{HOME}/.ptags.txt";
10 my %dirs = ();
11 my @found = ();
12
13 find \&file_wanted, grep {$_ ne "."} @INC;
14
15 blurt join("\n", sort @found), $outfile;
16
17 ###########################################
18 sub file_wanted {
19 ###########################################
20 my $abs = $File::Find::name;
21
22 # Avoid dupe dirs
23 $File::Find::prune = 1 if -d and
24 $dirs{$abs}++;
25
26 # Only Perl modules
27 return unless /\.pm$/;
28
29 my $d = PPI::Document->load($abs);
30
31 unless($d) {
32 WARN "Cannot load $abs ($! $@)";
33 return;
34 }
35 # Find packages and
36 # all named subroutines
37 $d->find(\&document_wanted);
38 }
39
40 ###########################################
41 sub document_wanted {
42 ###########################################
43 our $package;
44 my $tag;
45
46 if(ref($_[1]) eq
47 'PPI::Statement::Package') {
48 $tag = $_[1]->child(2)->content();
49 $package = $tag;
50
51 } elsif(ref($_[1]) eq
52 'PPI::Statement::Sub' and
53 $_[1]->name()) {
54 $tag = "$package\::" .
55 $_[1]->name();
56 }
57
58 return 1 unless defined $tag;
59
60 push @found, $tag . "\t" .
61 $File::Find::name . "\t" .
62 regex_from_node($_[1]);
63
64 return 1;
65 }
66
67 ###########################################
68 sub regex_from_node {
69 ###########################################
70 my($node) = @_;
71
72 my $regex = $node->content();
73
74 $regex =~ s/\n.*//gs;
75
76 while(my $prev =
77 $node->previous_sibling()) {
78 last if $prev =~ /\n/;
79 $regex = $prev->content() .
80 $regex;
81 $node = $prev;
82 }
83
84 $regex =~ s#[/.*[\]^\$]#\\$&#g;
85 return "/^$regex/";
86 }
Die Datei .vimrc im Home-Verzeichnis wird von vim beim
Programmstart eingelesen und erlaubt es, eine ganze Litanei von
Kommandos auszuführen, bevor vim die eigentliche Arbeit beginnt.
Wer die Standardeinstellungen interaktiv verschraubt hat, möchte diese
wahrscheinlich permanent festhalten. Statt die eingegebenen Kommandos
nochmals manuell in .vimrc einzutragen, genügt ein einfaches
:mkvimrc, mit dem vim alle zur Zeit gültigen Einstellungen in
~/.vimrc ablegt.
Unter [1] liegt eine Beispielkonfiguration mit allen heute vorgestellten Einstellungen. Wer Tipparbeit spart, hat mehr Zeit zum Denken!
01 version 6.0
02 :map !L iuse Log::Log4perl qw(:easy);<RETURN>Log::Log4perl->easy_init($DEBUG);<RETURN><ESC>
03 :map F o<ESC>43i#<ESC>yyosub {<ENTER><ESC>Pk$i
04 map f !Gperl -MText::Autoformat -e'autoformat{right=>70}'
05 set backspace=2
06 set fileencodings=utf-8,latin1
07 set formatoptions=tcql
08 set helplang=en
09 set history=50
10 set hlsearch
11 set ruler
12 set shiftwidth=4
13 :autocmd FileType perl :set cindent
14 :autocmd FileType perl :set expandtab
15 :autocmd Filetype perl :set smarttab
16 :nnoremap X :w<Enter>:!perl -c %<Enter>
17 :set tags=/home/mschilli/.ptags.txt
18 :set iskeyword+=:
tmpl Skript: http://perlmeister.com/scripts/tmpl
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |